Configuration Methods
You can configure scaling settings in three ways:In Your Application Code (Recommended)
Configure scaling directly in your application code using class parameters. This is the recommended approach for most scenarios as it keeps your configuration close to your code:Using CLI Commands
Adjust scaling settings for deployed applications using CLI commands. This is useful for production tuning without code changes:Note:Redeploying the application, by default, will not reset these settings, except for the code-specific settings. See Code-Specific Settings (Reset on Deploy) for details.
Updating Scale Settings on Redeployment
By default, redeploying an app uses the--no-scale behavior. This means the scale settings defined in your app’s code are ignored, and the app’s existing scale is preserved except for the code-specific settings.
To apply the scale settings from your app’s code during deployment, use the --reset-scale flag:
Code-Specific Settings (Reset on Deploy)
These settings must be set in your application code to persist. CLI changes are temporary and will reset to code-defined values on the next deployment.| Setting | CLI Flag | Why It’s Code-Specific |
|---|---|---|
max_multiplexing | --max-multiplexing | Depends on whether your code uses async handlers and can safely process multiple requests simultaneously |
startup_timeout | --startup-timeout | Depends on your application’s initialization requirements |
machine_type | --machine-types | Tied to your code’s hardware requirements |
Minimum Concurrency
Default: 0 Minimum concurrency is the minimum number of runners (application instances) that your app will keep alive at all times. Think of it as your app’s baseline capacity. If your app takes a while to start up, or if you anticipate sudden spikes in requests, setting a higher minimum concurrency can ensure there are always enough runners ready to respond immediately.In Code
Using CLI
Concurrency Buffer (Baseline)
Default: 0 The concurrency buffer baseline provides a cushion of extra runners above what’s currently needed to handle incoming requests. This is useful for apps with slow startup times, as it ensures there are always warm, ready runners to absorb sudden bursts of traffic without delays. Unlikemin_concurrency, which sets a fixed floor, concurrency_buffer aims to keep a specified number of additional runners available beyond the live demand.
The system first calculates the number of runners needed for the current request volume. It then adds concurrency_buffer to this number. The result is the total number of runners that will be kept alive.
Note:When you set a
concurrency_buffer higher than min_concurrency, it takes precedence over min_concurrency. This means the system will always keep at least the number of runners specified by the buffer (plus current demand), even if this is higher than your min_concurrency setting.Note:When you also set
concurrency_buffer_perc (see below), the number of concurrency buffer runners is the maximum of concurrency_buffer and concurrency_buffer_perc / 100 * request volume. This way concurrency_buffer acts as a baseline or minimum buffer.In Code
Using CLI
Concurrency Buffer % (Percentage)
Default: 0 App propertyconcurrency_buffer_perc allows you to set the concurrency buffer (see above) as a percentage of the current request volume. The numbers represent full percentage points, i.e. concurrency_buffer_perc = 20 means that the buffer will be 20% of the current request volume.
Note:When you also set
concurrency_buffer (see above), the number of concurrency buffer runners is the maximum of concurrency_buffer and concurrency_buffer_perc / 100 * request volume. Concurrency buffer percentage therefore only takes effect when it results in a higher buffer than concurrency_buffer.In Code
Using CLI
Max Concurrency
Max concurrency is the absolute upper limit for the total number of runners that your app can scale up to. This cap helps prevent excessive resource usage and ensures cost control, regardless of how many requests pour in.In Code
Using CLI
Keep Alive
Default: 10 seconds Keep alive is the amount of seconds a runner (beyond min concurrency) will be kept alive for your app. Depending on your traffic pattern, you might want to set this to a higher number, especially if your app is slow to start up.In Code
Using CLI
Scaling Delay
Default: 0 Scaling delay is the amount of seconds the system will wait for a request to be picked up by a runner before triggering a scale up of a runner. This is useful if you want to avoid scaling up too quickly and wasting resources. This is specially useful for apps with slow startup times.In Code
Using CLI
Max Multiplexing
Default: 1 Maximum multiplexing is the maximum number of requests that can be handled by a single runner at any time. This is useful if your app instance is capable of handling multiple requests at the same time, which typically depends on the machine type and amount of resources that your app needs to process a request.In Code
Using CLI
CLI changes to
max_multiplexing take effect immediately but will reset on next deployment. See Code-Specific Settings (Reset on Deploy) for details.Scaling Examples
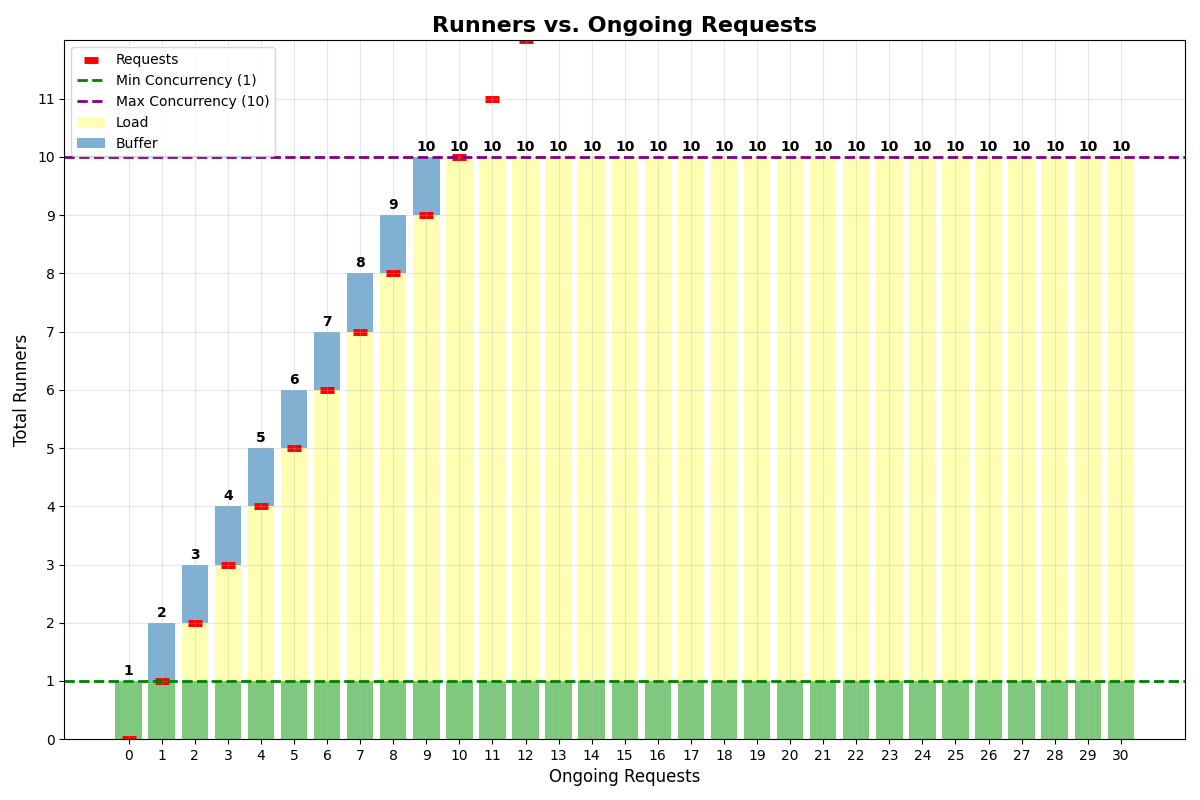
Same buffer and min concurrency
Let’s consider an app with:- Min concurrency: 1
- Concurrency buffer: 1
- Max multiplexing: 1
- Max concurrency: 10
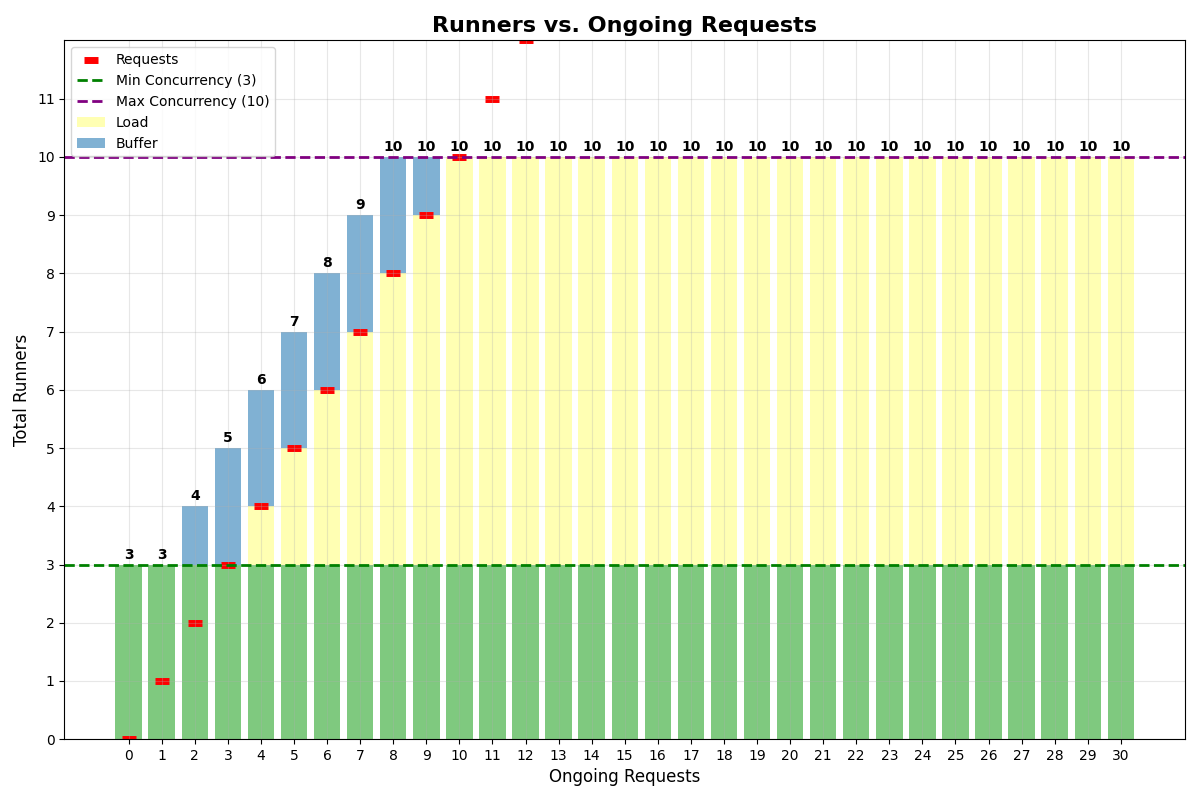
No multiplexing
Let’s consider an app with:- Min concurrency: 3
- Concurrency buffer: 2
- Max multiplexing: 1
- Max concurrency: 10
With multiplexing
Let’s consider an app with:- Min concurrency: 0
- Concurrency buffer: 2
- Max multiplexing: 4
- Max concurrency: 6
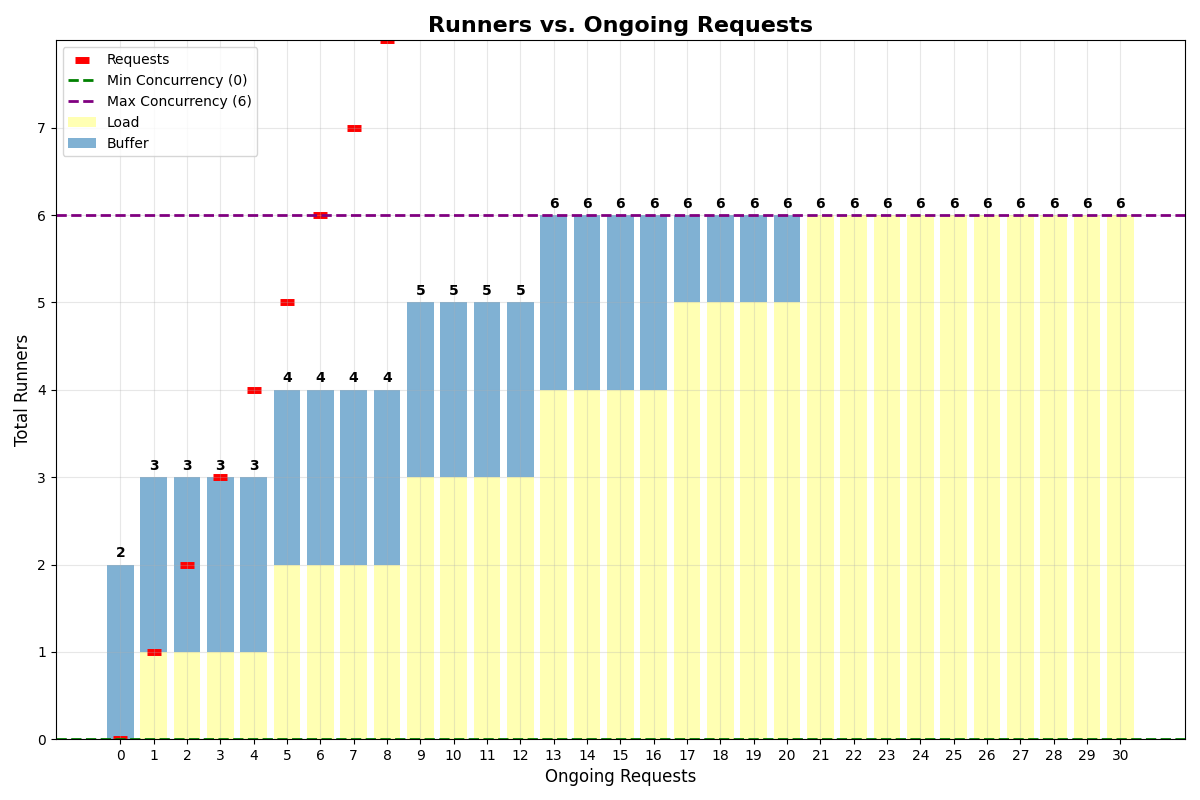
multiplexing of 4 is in place, a single runner can handle 4 requests at the same time.
Also notice that even if min concurrency is set to 0, the system will still keep 2 runners alive to handle the buffer.
Cost Optimization Strategies
- Start with conservative settings and adjust based on actual usage patterns
- Use concurrency buffer for apps with slow startup times instead of high min concurrency
- Enable multiplexing when your app can handle concurrent requests efficiently
- Monitor usage patterns and adjust scaling parameters accordingly
- Set reasonable max concurrency to prevent runaway costs